Data mining - Can you dig it?

I always think of the gold rush in the 19th century when I think of data mining. Just as these miners were looking to strike it rich in gold, data miners are hoping to strike it rich in insights. Data miners are trying to find that "golden nugget" of data or information that will help boost their business profits or take them from a struggling start up to a million or billion dollar going concern.

Data mining has been around for a long time but with the improvements in computing power and in the era of big data, it is a key component within data science. It is also used interchangeably with the term Knowledge Discovery. There are really two big areas that data mining focuses on: descriptive modeling and predictive modeling.
Descriptive Modeling
Descriptive modeling is really about finding relationships and similarities in your data. Some of the fun models include cluster analysis and principal components analysis (PCA).
Cluster analysis is when you are trying to find different ways to group similar elements together. For example, say you want to determine the types of customers you have because you want to put them in similar groupings for marketing purposes. You might use a cluster analysis to create customer “personas” to reduce your marketing efforts while still speaking to the key traits of each person in the group.
In comparison, Principal Components Analysis (PCA) is when you have too many variables to describe your data set and you are trying to get to just a small few to make your analysis easier but still accurate. For example, let’s say you have 50 possible variables that could affect whether a patient admitted for heart failure survives or does not. A PCA could help you reduce that to 5 or 6 “principal components” (variables) without losing any key information. Now, that sounds like it would be a lot easier to focus on 5 or 6 things to improve for a patient rather than guessing at which of the original 50 variables to focus on in the hopes it would improve outcomes.
Predictive Modeling
Predictive modeling is about trying to determine what will happen in the future. It is important to note that most predictive models use an element of probability to determine future outcomes. Some of the most popular techniques are:
- Regression
- Decision trees
- Neural networks
Regression models look at the relationship between a dependant variable and various independent variables. There are quite a few out there but the two most common are:
-
Simple and Multiple Linear Regression models are what are often taught (and hopefully learned) in introductory statistics classes but they have a lot of restrictions. The biggest is that the relationship between dependent and independent variables is approximately linear (a straight line). There are several other restrictions and if they cannot be met, that’s where other regression models are useful.
-
My personal favorite is the logistic regression model. Not sure why. Perhaps it’s because I spent so much time on it during my Master’s thesis that it holds a special place in my heart. But regardless of the reason, it’s a pretty cool – and very useful – technique for predictive modeling. And the biggest assumption it relies on is that there is no multicollinearity, which is a fancy term that means the variables you are using as inputs (independent) are not correlated.
The output of a logistic regression model is a number between 0 and 1, indicating the probability that the event you are trying to predict will happen. Closer to 0 and it’s unlikely to happen while closer to 1 means it’s almost certain to happen. This model provides a probability for every person-of-interest in your database. So, if you want to know how likely it is that a customer will buy your product, a patient will not survive, or a criminal will be rehabilitated then logistic regression can be a good technique to try.
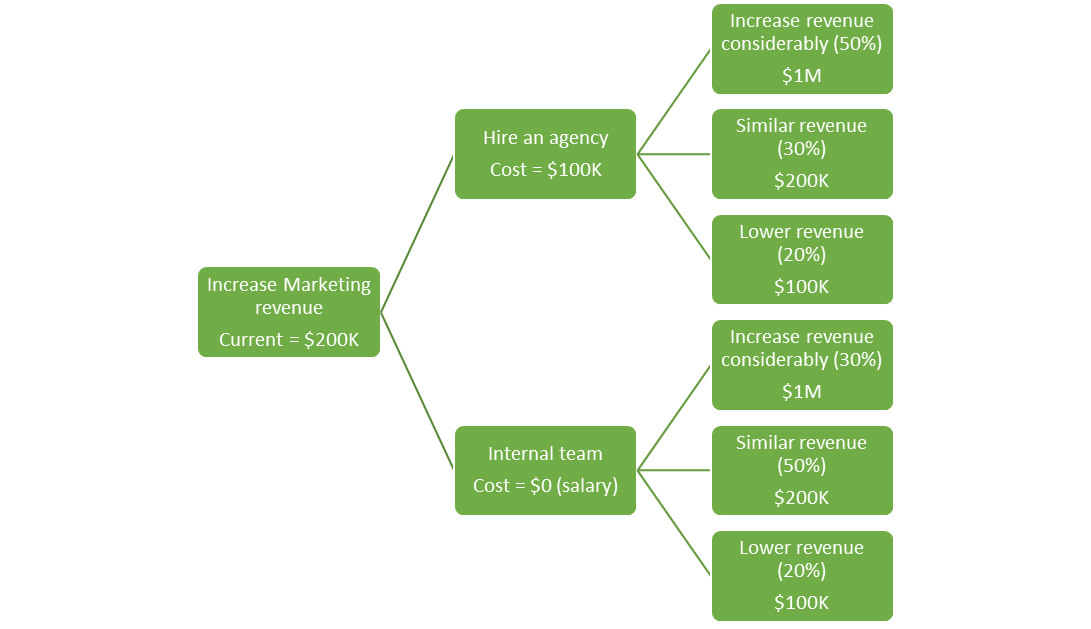
Decision trees are visual diagrams that help to break down a complex situation. It usually starts with one point (node) and branches off. Honestly, it doesn’t look that much different from a family tree that starts with one point – you – then branches off to parents, grandparents and other ancestors. The key difference is that each node on the branch contains a probability of that event occurring. Decision trees are very useful because they are visual and can break down a complex decision into smaller components.
Neural networks are computer algorithms that try to mimic how the human brain works and learns by looking for patterns and making predictions. These are also referred to as Artificial Neural Networks (ANNs) and that’s about all I’m going to say about them. This is a very mathematical and computing intensive area. I’m not very familiar with it but I included it here because it is considered an element of data mining due to its ability to analyze and predict using data.
Final Thoughts
Although the term data mining is not as commonly used in 2023 as machine learning or artificial intelligence (AI), it is a very valuable technique that is still used to process and analyze large sets of data as a means to uncover relationships, patterns and trends, or help predict future outcomes. So, next time you or a colleague are data mining and hoping to strike it rich in insights, I won't blame you if you start humming the tune "Heigh Ho" from the movie Snow White.