Data Terminology - Part I

As new technologies emerge and the data landscape evolves, it’s easy to get lost in the sea of jargon. Terms like data wrangling, data lake, ETL and data democratization are thrown around frequently, but what do they all mean and how do they relate to one another?
In this and my next 2 posts, I’ll break down and compare some of the what I’ve seen as commonly used data terms using a visualization bring clarity to the words. Through these posts, I hope you will get a clearer understanding of how all this terminology fits into the broader data ecosystem.
In this first post, I will focus on the terminology that happens before analysis even starts. Many people have said that 80% of the work in data happens in this part and if the amount of terminology is any indication, they would definitely be correct! 😄
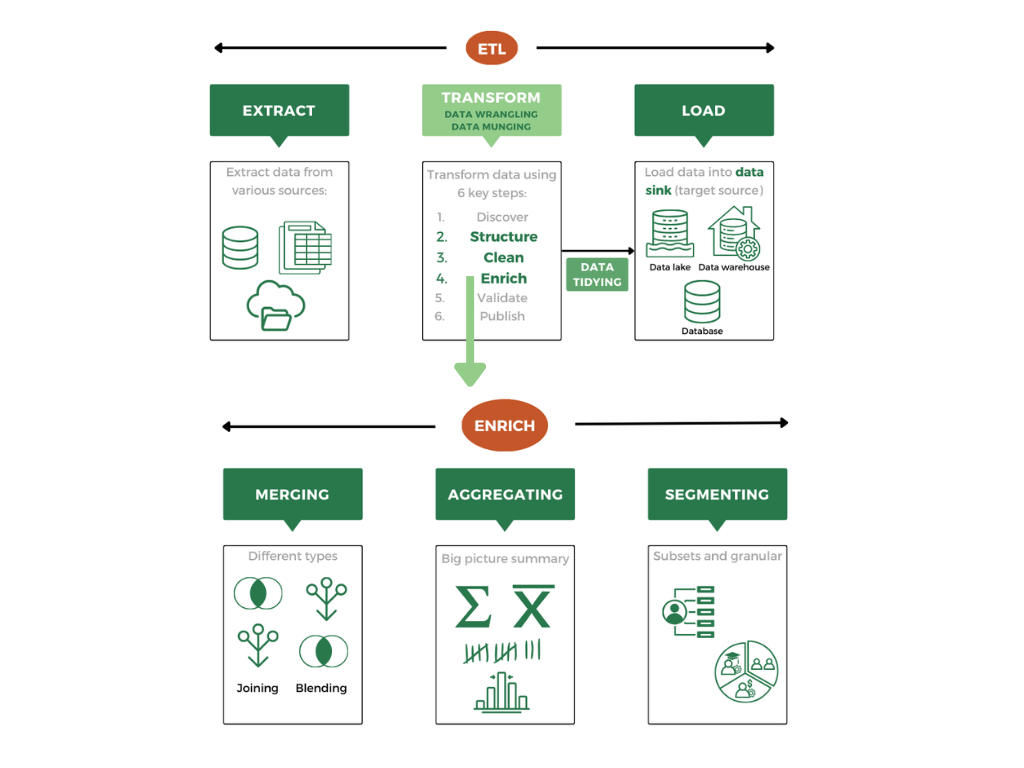
ETL vs. Data Transformation
The terms ETL (Extract, Transform, Load) and data transformation are often used in a similar context but they do not mean the same thing.
-
ETL: stands for extract-transform-load. This is a structured process where data is first extracted from a source, then it is transformed into a format suitable for analysis (including structuring, cleaning and enriching), and then loaded into a target system, such as a database or warehouse.
-
Data Transformation: specifically refers to the middle step in the process of changing data from one format or structure to another. This transformation step is part of the ETL pipeline but can also occur independently outside of ETL processes. This is also where data wrangling / munging happen.
In summary, ETL is a complete data pipeline while data transformation is the middle step that reshapes data for use.
 Data Wrangling vs. Data Munging
Data Wrangling vs. Data Munging
Data wrangling and data munging are often used interchangeably, but they have subtle distinctions. Data wrangling is also used more frequently and has more defined processes.
-
Data Wrangling: the process of discovering, structuring and cleaning, enriching, validating and publishing data. It often involves handling missing values, correcting data formats, removing duplicate values, identifying/removing incorrect or irrelevant data, or enriching the data by merging, blending, segmenting or aggregating. Some definitions also suggest data wrangling uses more automation and tools compared to data munging.
-
Data Munging: has a similar purpose (and even process) as data wrangling but with a focus on quick, sometimes less structured or ad-hoc approaches. Some definitions suggest data munging is a more manual process that (could possibly) result in higher quality output because it is a more iterative and hands-on process.
Both data wrangling and munging are about transforming data and getting it ready for analysis. Wrangling is viewed as more systematic while munging, it has been suggested, is a more hands-on, sometimes improvised approach.
 Data Cleaning vs. Data Tidying
Data Cleaning vs. Data Tidying
Data structuring / cleaning are sub-sets of the data wrangling / munging process while data tidying is the output of the process.
-
Data Structuring / Cleaning: comes after you’ve had a chance to look at the data and assess its quality and where it needs some TLC. Undoubtedly, the data will require structuring: dealing with missing values and changing or ensuring formats are consistent. Here you are making sure the data is uniform, valid and complete. Data cleaning looks at other elements such as duplicates, errors, contradictory data. Here you are ensuring the data is accurate, reliable and consistent.
-
Data Tidying: (also called “tidy data”) works with already structured and cleaned data and gives it a different kind of structure and organization so it is ready for analysis. Oftentimes “tidy data” means there is a row-column structure where variables are in columns and observations are in rows.
Data structuring and cleaning are making sure the data itself is clean while data tidying takes the output of wrangling or munging and structures and organizes the overall data set.
 Data Joining vs. Data Blending
Data Joining vs. Data Blending
When you work with multiple datasets, you’ll often need to combine data among datasets. That’s where data merging comes into play. These are also part of the enriching step in data wrangling / munging.
-
Data Merging: is the umbrella term for anytime you want to combine two or more records or dataset into one record or data set.
-
Data Joining: involves combining two or more datasets by matching specific key fields (like customer IDs). The data needs to be compatible, often requiring a shared schema. Joining combines the data first and then aggregates the joined / combined data after.
-
Data Blending: refers to the process of combining data from different sources or systems that don’t necessarily have a common schema or key. It’s a more flexible and complex process, often used when dealing with disparate data sources. Data blending will aggregate the data in each data set first and then blend it with other data sets after.
While both are types of data merging, joining is about aligning datasets with common fields while blending involves mixing diverse sources into a cohesive dataset for analysis.
 Aggregation vs. Segmentation
Aggregation vs. Segmentation
Oftentimes, another way to enrich your data as part of data wrangling / munging is to aggregate or segment it for deeper analysis.
-
Data Aggregation: summarizes or groups data into high-level metrics like sums, averages, or counts. For example, aggregating sales data by month or region helps provide insights into overall performance.
-
Data Segmentation: divides data into distinct subsets based on certain criteria, like customer demographics or behaviors. Segmentation allows for more targeted analysis by focusing on smaller, meaningful groups.
Aggregation provides a big-picture summary while segmentation dives deeper into individual data groups for more granular insights.
 Data sinks
Data sinks
The terms under data sink are often confused, but they serve different purposes and are generally related to the load part of ETL.
-
Data Sink: is the umbrella term for systems designed to store data from multiple data sources. Data sinks include databases, data lakes and data warehouses.
-
Database: is a system for storing and managing data in a structured format, typically using tables. Databases are ideal for transactional applications and usually used for reporting purposes. Complex queries are costly and harder to perform.
-
Data Warehouse: similar to a database where it is a centralized repository designed to store large amounts of structured data from multiple sources; however, data warehouses tend to be optimized for analysis even though they can also be used for reporting. As a result, complex queries are easier to perform.
-
Data Lake: is a storage system or repository that holds vast amounts of raw, unstructured data in its native format until needed. Data lakes are flexible and can handle various data types, including text, video, and log files. They are often used for big data analytics, where data can be processed and structured later as needed.
Databases handle day-to-day operations, data warehouses are designed for structured analysis and data lakes store large volumes of raw, often unstructured, data for later use.
Part 1 Conclusion and References
And that takes us to the end of terminology relating to getting the data ready for further analysis. Below, I am including links to the references I used to supplement my own experience and knowledge in these areas.
Please also check out my next 2 posts where I discuss some of the terminology in analysis and communication approaches as well as data management.